Augmentation and Amplification
Multimedia live stream performance, 2019
SO⅃OS
July 30, 2020
Fridman Gallery and CT::SWaM present SO⅃OS.
Operating within NYC’s shelter-in-place guidelines, only one person – the performer – is present. Equipped with multiple microphones and cameras (mixed remotely), the space itself becomes a generative agent for the performer.
“Augmentation and Amplification,” was presented as a live-streamed project performed during the global pandemic, on July 30th, 2020. The performance continued my ongoing investigation into creative collaborations between humans and technology, fusing neural diversity, inclusive creative expressions, and adaptability within isolation and confinement.
Vocalist/dancer Mary Esther Carter was alone in the space. All other technology, including multiple microphones and cameras were run and mixed remotely, allowing the performance to operate in accordance with NYC’s shelter-in-place guidelines. Her vocal partner, an autonomous A.I. entity, exists only online. The live-stream performance interwove live action in the gallery, translucent video overlays and opaque video imagery, with a combination of live, pre-recorded, and tech-generated audio.
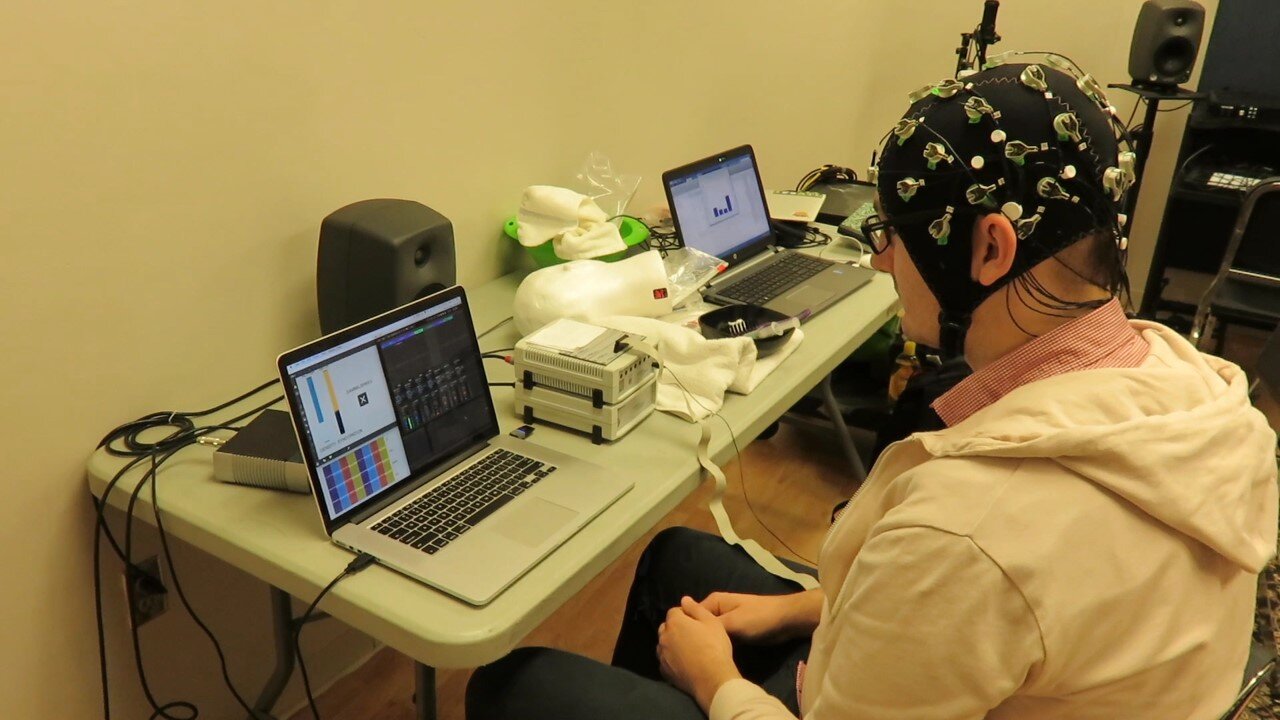
The work opened with images of dramatic volcanic landscapes as a narrator described global seismic shifts. This video dissolves to reveal Mary, in real-time, pacing a small empty space. Mary dropped to the ground and performed an anxiety-producing series of movements. The percussive soundtrack for Mary’s dance sequence was generated by electroencephalogram (EEG) sonification, the process of turning data into sound. Composer and music technologist Richard Savery used his own brainwaves to control a drum-set, producing brainwave-beats.
Gasping for breath and exhausted from the Sisyphean dance movement, Mary hears a disembodied voice in the space. Answering
the voice, Mary and “A. I. Anne” begin an improvised duet of vocalizations.
A.I. Anne is a machine learning entity created by Richard Savery. Trained on Mary’s voice, A.I. Anne is named and patterned after my aunt,
who was severely autistic and nonverbal due to apraxia. The “human” Anne could emotively hum, but was never able to speak. The virtual
A.I. Anne has the ability to vocalize, but not create language. Using deep learning combined with semantic knowledge, A.I. Anne can
generate audible emotions and respond to emotions.
The performance ends with video footage of my aunt Anne rocking in a chair. The narrator describes her end of life as she was taken off
of a ventilator and speaks of the profound affect Anne had on the world and those who knew her.